18.1.2 MySQL Cluster 노드, 노드 그룹 복제 및 파티션
이 섹션에서는 MySQL Cluster가 저장하는 데이터를 분할 및 복제하는 방법을 설명합니다.
다음의 각 단락에서는이 주제를 이해하는 데 중심이되는 몇 가지 개념에 대해 설명합니다.
(데이터) 노드 복제 (노드가 속한 노드 그룹에 할당 된 파티션 (다음을 참조하십시오) 사본)를 저장하는 ndbd 프로세스입니다.
각 데이터 노드는 별도의 컴퓨터에 배치하도록하십시오. 하나의 컴퓨터에서 여러 ndbd 프로세스를 호스트 할 수 있지만, 이러한 구성은 지원되지 않습니다.
일반적으로 ndbd 프로세스를 언급 할 때는 '노드'와 '데이터 노드 "를 구별하지 않고 사용합니다. 이 설명에서 관리 노드 (ndb_mgmd 프로세스)와 SQL 노드 (mysqld 프로세스)을 언급 할 때는 그렇게 명시합니다.
노드 그룹 노드 그룹은 하나 이상의 노드로 구성된 파티션 또는 복제 (다음 항목을 참조하십시오) 세트를 포함합니다.
MySQL Cluster의 노드 그룹의 수를 직접 구성 할 수 없습니다. 이것은 여기에 같이 데이터 노드의 수와 복제 수 ( NoOfReplicas 구성 매개 변수) 함수입니다.
[number_of_node_groups] =number_of_data_nodes/NoOfReplicas
따라서 4 개의 데이터 노드를 포함 MySQL Cluster에서 config.ini 파일의 NoOfReplicas 가 1로 설정되어있는 경우 4 개의 노드 그룹이 존재하고 NoOfReplicas 가 2로 설정되어있는 경우는 2 개의 노드 그룹이 존재하고 NoOfReplicas 가 4로 설정되어있는 경우는 하나의 노드 그룹이 존재합니다. 복제에 대해서는이 섹션 뒷부분합니다. NoOfReplicas 대한 자세한 내용은 섹션 18.3.2.6 "MySQL Cluster 데이터 노드의 정의" 를 참조하십시오.
MySQL Cluster 내의 모든 노드 그룹에 같은 수의 데이터 노드가 포함되어 있어야합니다.
실행중인 MySQL Cluster에 온라인으로 새로운 노드 그룹 (및 그 결과로서의 새로운 데이터 노드)를 추가 할 수 있습니다. 자세한 내용은 섹션 18.5.13 "MySQL Cluster 데이터 노드의 온라인 추가" 를 참조하십시오.
파티션이 클러스터에 저장되는 데이터의 일부입니다. 클러스터에 참여하는 노드와 같은 수의 클러스터 파티션이 존재합니다. 각 노드는 그 노드에 할당 된 파티션 하나의 복사 (즉, 적어도 1 개의 복제본)을 클러스터에서 사용할 수있는 상태로 유지하는 역할을 담당합니다.
복제는 완전히 하나의 노드에 속합니다. 노드는 여러 복제본을 저장할 수 있습니다 (그리고 일반적으로 그렇게합니다).
NDB 및 사용자 정의 분할 일반적으로 MySQL Cluster는 NDBCLUSTER 테이블을 자동으로 분할합니다. 그러나 NDBCLUSTER 테이블에 사용자 정의 파티셔닝을 적용 할 수 있습니다. 여기에는 다음과 같은 제한이 있습니다.
NDB테이블에는KEY및LINEAR KEY파티셔닝 만 사용할 수 있습니다.ndbd를 사용하는 경우,
NDB테이블에 대해 명시 적으로 정의 할 수있는 파티션의 최대 수는8 *[number of node groups]ndbmtd를 사용하는 경우이 최대
MaxNoOfExecutionThreads구성 매개 변수의 값에 의해 결정되는 로컬 쿼리 핸들러 쓰레드의 수에 영향됩니다. 이러한 경우NDB테이블에 대해 명시 적으로 정의 할 수있는 파티션의 최대 수는4 * MaxNoOfExecutionThreads *[number of node groups]자세한 내용은 섹션 18.4.3 "ndbmtd - MySQL Cluster 데이터 노드 데몬 (멀티 스레드)" 를 참조하십시오.
MySQL Cluster와 사용자 정의의 분할에 관한 자세한 내용은 섹션 18.1.6 "MySQL Cluster의 알려진 제한" 및 섹션 19.6.2 "스토리지 엔진 관련 파티셔닝 제한" 을 참조하십시오.
복제 이것은 클러스터 파티션 복사합니다. 복제 노드 그룹의 각 노드에 저장됩니다. 파티션 복제라는 것도 있습니다. 복제의 수는 노드 그룹 당 노드 수와 동일합니다.
다음 그림은 4 개의 데이터 노드를 포함 MySQL Cluster를 나타냅니다. 이러한 노드는 각각 2 노드로 이루어진 2 개의 노드 그룹에 배치되어 있습니다. 노드 1과 2는 노드 그룹 0에 속하는 노드 3 및 4는 노드 그룹 1에 속합니다. 여기에는 데이터 (ndbd) 노드 만 표시하고 있습니다. 제대로 작동하는 클러스터는 클러스터 관리 용 ndb_mgm 프로세스와 클러스터에 저장되어있는 데이터에 액세스하기위한 SQL 노드가 하나 필요하지만이 그림은 이해를 돕기 위해이를 생략하고 합니다.
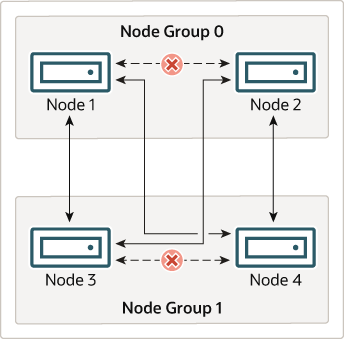
클러스터에 저장된 데이터는 0,1,2,3의 번호가 붙은 4 개의 파티션으로 분할되어 있습니다. 각 파티션은 동일한 노드 그룹에 (여러 복사본) 저장됩니다. 파티션은 다음과 같이 각 노드 그룹에 교대로 저장됩니다.
파티션 0은 노드 그룹 0에 저장됩니다. 주 복제본 (주 복사본)이 노드 1에 저장된 백업 복제 (파티션의 백업 복사본)가 노드 2에 저장됩니다.
파티션 1은 다른 노드 그룹 (노드 그룹 1)에 저장됩니다. 이 파티션의 주 복제본이 노드 3에 저장되고 백업 복제가 노드 4에 저장됩니다.
파티션 2는 노드 그룹 0에 저장됩니다. 그러나 그 두 개의 복제본은 파티션 0과는 반대로 배치됩니다. 주 복제본이 노드 2에 저장된 백업 복제본이 노드 1에 저장됩니다.
파티션 3은 노드 그룹 1에 저장되어 그 2 개의 복제본은 파티션 1과는 반대로 배치됩니다. 즉, 기본 복제본이 노드 4에 저장된 백업 복제가 노드 3에 저장됩니다.
이것은 MySQL Cluster의 지속적인 운영에 관하여 다음과 같은 의미를 가지고 있습니다. 클러스터에 참여하는 각 노드 그룹에서 하나의 노드가 작동하는 한, 클러스터는 모든 데이터의 완전한 사본을 보관하고 실행 가능한 상태를 유지합니다. 이것을 다음의 그림과 같습니다.
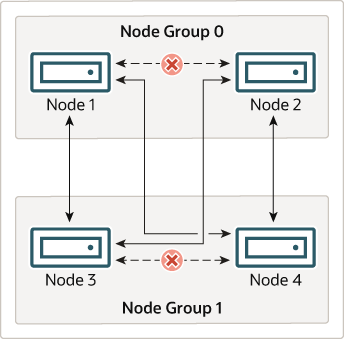
이 예에서는 클러스터는 각각 두 개의 노드를 포함하는 두 개의 노드 그룹으로 구성되어 있으며, 클러스터를 "생존"시키려면 노드 그룹 0의 적어도 하나의 노드와 노드 그룹 1의 적어도 하나의 노드 조합 (그림의 화살표로 나타낸 것)이 있으면 충분합니다. 그러나 어느 노드 그룹의 두 노드에 장애가 발생하면 나머지 2 개의 노드 (X 표시 한 화살표로 나타낸 것)는 부족합니다. 두 경우 모두 클러스터에서 파티션 전체가 소실하는 모든 클러스터 데이터의 전체 집합에 대한 액세스를 제공 할 수 없게됩니다.