18.6.10 MySQL Cluster Replication:멀티 마스터와 순환 복제
다중 마스터 복제 MySQL Cluster를 사용하는 것은 가능합니다 (대부분의 MySQL Cluster 간의 순환 복제를 포함합니다).
순환 복제 예제 다음 몇 단락에서는 다음과 같은 복제 설정의 예를 검토합니다. 이 설정은 번호가 1,2,3의 3 개의 MySQL Cluster로 구성된 클러스터 1은 클러스터 2의 복제 마스터로 동작하고 클러스터 2 클러스터 3의 마스터로 작동 클러스터 3 클러스터 1의 마스터 로 작동합니다. 각 클러스터는 2 개의 SQL 노드를 가지고 SQL 노드 A와 B는 클러스터 1에 속하고, SQL 노드 C와 D는 클러스터 2에 속하는 SQL 노드 E와 F는 클러스터 3에 속해 있습니다.
이러한 클러스터를 사용하는 순환 복제는 다음 조건을 충족 한 지원됩니다.
모든 마스터와 슬레이브의 SQL 노드는 같은
복제 마스터 및 슬레이브로 동작하는 모든 SQL 노드가
--log-slave-updates옵션을 사용하여 시작된다
이 유형의 순환 복제 설정은 다음 그림과 같습니다.
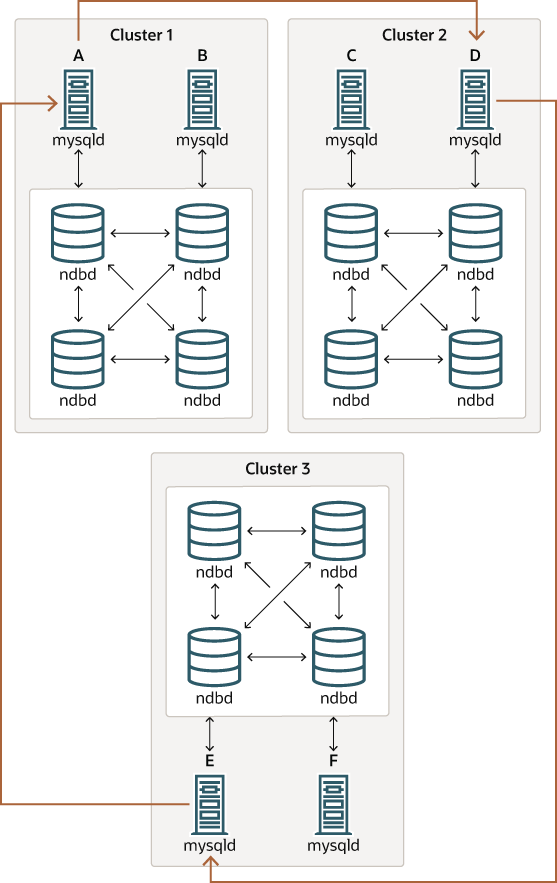
이 시나리오에서는 클러스터 1의 SQL 노드 A는 클러스터 2의 SQL 노드 C에 복제, SQL 노드 C는 클러스터 3의 SQL 노드 E에 복사, SQL 노드 E는 SQL 노드 A에 복제합니다. 즉, 복제 라인 (그림의 빨간색 화살표)은 복제 마스터 및 슬레이브로 사용되는 모든 SQL 노드를 직접 연결합니다.
여기에서 같이 모든 마스터 SQL 노드가 반드시 슬레이브라는 것은 아니다 경우에 순환 복제를 설정할 수 있습니다.
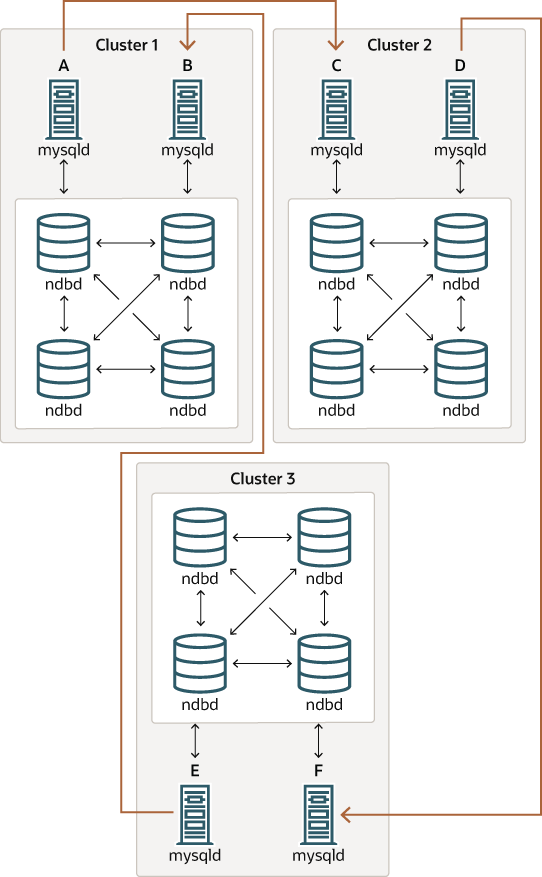
이 경우 각 클러스터의 다른 SQL 노드는 복제 마스터 및 슬레이브로 사용됩니다. 그러나 SQL 노드를 --log-slave-updates 를 사용하여 시작할 필요가 없습니다. 복제 라인 (이것도 그림의 빨간색 화살표)가 연속하지 않은 MySQL Cluster의이 유형의 순환 복제 방식은 가능성은 있지만 아직 완전히 테스트되지 않기 때문에 실험적인 것이라고 생각하게합니다.
NDB 기본 백업 및 복원을 사용하여 슬레이브 MySQL Cluster의 초기화 순환 복제를 설정하려면 백업을 만들 MySQL Cluster에서 관리 클라이언트의 BACKUP 명령을 사용하고 ndb_restore를 사용하여 다른 MySQL Cluster에서이 백업을 적용하면 슬레이브 클러스터를 초기화 할 수 있습니다. 그러나 이는 바이너리 로그가 리플리케이션 슬레이브로 동작하는 두 번째 MySQL Cluster의 SQL 노드에 자동으로 생성되는 것은 아닙니다. 바이너리 로그가 생성되도록하려면 대상 SQL 노드에서 SHOW TABLES 문을 실행해야합니다. 이것은 START SLAVE 를 실행하기 전에 수행해야합니다.
이것은 향후 릴리스에서 지원하려는 알려진 문제입니다.
다중 마스터 페일 오버의 예이 섹션에서는 3 개의 MySQL Cluster의 서버 ID가 1, 2 및 3 인 다중 마스터의 MySQL Cluster 복제 설정에서 장애 조치에 대해 설명합니다. 이 시나리오에서는 클러스터 1은 클러스터 2 및 3에 복제 클러스터 2도 클러스터 3에 복제합니다. 이 관계는 여기에 나와 있습니다.

즉, 데이터는 클러스터 1에서 클러스터 3에 두 개의 서로 다른 루트를 통해 (직접 및 클러스터 2를 통해) 복제됩니다.
다중 마스터 복제에 참여하는 모든 MySQL 서버가 반드시 마스터와 슬레이브의 역할을해야한다 것은 아니고 특정 MySQL Cluster가 다른 복제 채널이 다른 SQL 노드를 사용할 수 있습니다. 이러한 경우를 보여줍니다.

리플리케이션 슬레이브로 작동하고있는 MySQL 서버는 --log-slave-updates 옵션을 사용하여 실행해야합니다. 또한 어떤 mysqld 프로세스에서이 옵션이 필요하거나 이전 그림에 나와 있습니다.
--log-slave-updates 옵션을 사용하여 복제 슬레이브로 작동하지 않는 서버에 영향을주지 않습니다.
복제 클러스터 중 하나가 중지 된 경우 장애 조치의 필요성이 생깁니다. 이 예에서는 클러스터 1의 서비스가 손실되고 따라서 클러스터 3 클러스터 1의 업데이트 두 가지 소스를 잃게 케이스를 검토합니다. MySQL Cluster 간의 복제가 비동기이기 때문에 클러스터 1에서 직접 발생하는 클러스터 3의 업데이트가 클러스터 2를 통해받은 업데이트보다 새로운 것이라는 보장은 없습니다. 클러스터 1의 업데이트에 대해 클러스터 3가 확실히 클러스터 2에 따라 잡을 것으로 이에 대처할 수 있습니다. 즉, MySQL 서버에 대해 처리되지 않은 업데이트를 MySQL 서버 C에서 서버 F에 복제해야합니다.
서버 C에서 다음 쿼리를 실행합니다.
mysqlC> SELECT @latest:=MAX(epoch)
-> FROM mysql.ndb_apply_status
-> WHERE server_id=1;
mysqlC> SELECT
-> @file:=SUBSTRING_INDEX(File, '/', -1),
-> @pos:=Position
-> FROM mysql.ndb_binlog_index
-> WHERE orig_epoch >= @latest
-> AND orig_server_id = 1
-> ORDER BY epoch ASC LIMIT 1;
적절한 인덱스를 ndb_binlog_index 테이블에 추가하여이 쿼리의 성능을 향상 할 수 있기 때문에 장애 복구 시간이 크게 단축 될 수 있습니다. 자세한 내용은 섹션 18.6.4 "MySQL Cluster 복제 스키마 및 테이블" 을 참조하십시오.
@file 및 @pos 값을 수동으로 서버 C에서 서버 F에 복사를합니다 (또는 응용 프로그램처럼 실행시킵니다). 다음 서버 F에서 다음 CHANGE MASTER TO 문을 실행합니다.
mysqlF> CHANGE MASTER TO
-> MASTER_HOST = 'serverC'
-> MASTER_LOG_FILE='@file',
-> MASTER_LOG_POS=@pos;
이 실행하면 MySQL 서버 F에서 START SLAVE 명령문을 실행한다 서버 B에서 생긴 부족한 업데이트 서버 F에 복제됩니다.
CHANGE MASTER TO 문은 IGNORE_SERVER_IDS 옵션도 지원합니다. 이 옵션은 쉼표로 구분 된 서버의 ID를 사용하여 해당 서버에서 발생한 이벤트가 무시됩니다. 자세한 내용은 섹션 13.4.2.1 "CHANGE MASTER TO 구문" 및 섹션 13.7.5.35 "SHOW SLAVE STATUS 구문" 을 참조하십시오.